Articol realizat de Tiberius Margarit – scrie articole interesante pe stapanidebani.ro şi este autorul cărţii de educaţie financiară “Legile Banilor Tăi”.
Reușitele financiare personale sunt rezervate nouă, tuturor. Celor care nu acceptă riscul agresiv, în egală măsură cu cei care își asumă riscuri. Indiferent ce tip de om ești, există o combinație care ți se potrivește…
Am fost și sunt încă fascinat de Charles Munger. Ca aplicabilitate practică, pornind de la citatul său de referință:
“Prima sută de mii este cea mai mare c..vă” – Charles Munger
(sper să treceți peste aspectul frust al ultimului cuvânt ales de autor ca licență poetică pentru echivalentul “greu”), am fost uluit să înțeleg ce înseamnă să îți setezi ca reper prima sută de mii, cu adevărat.
Apoi, am simțit nevoia să sap puțin mai adânc la ideile din jurul acestei borne și am ajuns la ideea că, funcție de cum ne raportăm la acest obiectiv, noi, investitorii ne împărțim în patru categorii, așa cum apare în acest articol, găzduit cu amabilitate de Laurențiu Mihai pe blogul lui.
Acum am vrut să merg mai departe. Dacă nu ești chiar prima dată pe SdB, probabil că știi că sunt adeptul înverșunat al unui plan financiar. Asta înseamnă că abordările din Finanțele Personale de genul “pun 5.000 de Euro pe BET-TR sau MSCI -World sau Facebook și văd ce iese” sau “Vreau randamentul cel mai mare” nu sunt pentru Stăpânii de Bani.
Așadar, vreau să știu ce trebuie să fac, dacă mi-am setat obiectivul să ating prima 100.000 în 10 ani. Și vreau să-mi schițez un mini plan!
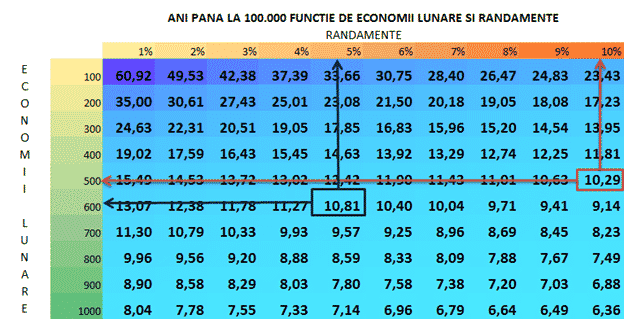
Dacă mergi pe calea clasică, atunci te gândești că ai auzit ca poți să mergi pe 10% medie multi anuală de creștere a burselor, așa că îți calculezi un drum astfel: pun 500 de lei (de exemplu) lunar îi capitalizez anual @ 10% și atunci, conform tabelului, în 10, 29 ani ar trebui să am obiectivul atins, adică într-un cont cu numele meu pe el, după atâția ani s-a strâns prima sută de mii de lei.

Dar în 10 ani se pot întâmpla multe pe piața de capital. Mai sunt și alte opțiuni?
Dacă te uiți cu atenție pe tabelul acela, vei vedea că dacă mergi pe varianta în care economisești 600 de lei în loc de 500 pe lună și cauți să ajungi tot acolo în 10 ani și ceva, atunci poți merge pe instrumente care îți aduc 5% pe an.
Sincer mă așteptam să fie diferențe, dar nu așa de mari. Opțiunea aceasta a doua îmi arată că, dacă pun doar 100 de lei în plus pe lună pot alege instrumente mult mai sigure. Adică pentru 3 lei în plus pe zi, eu pot alege instrumente de investiții din o cu totul altă gamă. Dacă asociezi riscul cu nivelul de 10%, atunci 5% înseamnă un risc de două ori mai mic!!!
Ok, dar să zicem că eu sunt un tip temător, mă cam sperie și ideea de instrumente precum, să spunem – obligațiuni municipale, am altă variantă?
Tot uitându-ne pe tabel, vedem că, dacă mergi pe o sumă economisită de 700 pe lună pot alege instrumente care sunt mult mai aproape de setarea mea mentală.

Așadar cu 700 de lei pe lună @ 3% anual ajungi tot la același obiectiv: 100.000 în 10 ani!
Cred că ai înțeles ce vreau să fac mai departe. Am de gând să explorez și șansele celor care nu au încredere decât în instrumentele considerate super sigure, dar care nu aduc decât 1 %. Ei bine și aceștia pot intra în posesia aceluiași premiu tot după – aproximativ – 10 ani, dacă economisesc 800 de lei lunar.
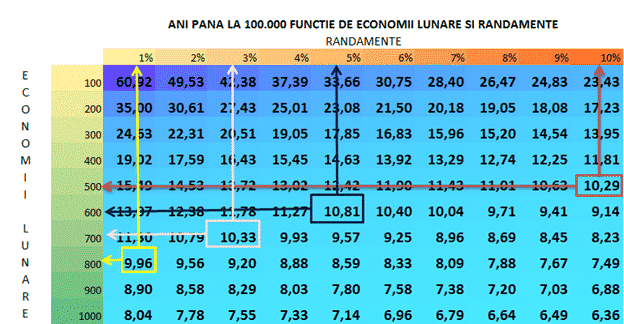
Concluzii:
- Nu există o singură cale între punctul financiar A și punctul financiar B, pentru că, în lumea investițiilor (pe cazul dat):
- 500 lei@ 10% = 600 lei @ 5% = 700 lei @ 3% = 800 lei @ 1%
- La același obiectiv poți ajunge și mergând cu viteze muuult micșorate, astfel încât să poți lua curbele în siguranță, dacă vrei.
- Absolut toate tipologiile de investitori au locul lor rezervat în urmărirea obiectivelor lor. Asta dacă ai un obiectiv! Care obiectiv este o parte a unui plan… Si nu, “Pun 10% din venitul meu lunar deoparte (urăsc acest cuvânt!) sau în (pune tu aici ce instrument de investiție vrei)”, NU ESTE PLAN FINANCIAR. Fie și pentru faptul că nu are obiectiv…
- De aceea, prin alegerile mele, făcute pe baza profilului meu investițional, majoritatea investițiilor mele sunt atât de plicticoase (nu au pic de fior de adrenalină în ele), încât am rețineri să le expun public!
Articol realizat cu ajutorul lui Tiberius Margarit. Scrie articole interesante pe stapanidebani.ro şi este autorul cărţii de educaţie financiară “Legile Banilor Tăi”.






